东京--(美国商业资讯)--东芝电子元件及存储装置株式会社(“东芝”)今日宣布成功开发出一款汽车应用图像识别系统级芯片(SoC),与东芝上一代产品相比,该产品使深度学习加速器的速度提升10倍,功率效率提高4倍[1]。该技术成果的详情于2月19日在旧金山举行的2019 IEEE国际固态电路会议(ISSCC)上公诸于众。
此新闻稿包含多媒体内容。完整新闻稿可在以下网址查阅:https://www.businesswire.com/news/home/20190226005488/en/
自动紧急刹车等先进驾驶员辅助系统可提供越来越先进的功能,但实现这些功能需要图像识别系统级芯片在低功耗条件下高速识别道路交通信号和路况。
深度神经网络(DNN)是模仿大脑神经网络的算法,与传统模式识别和机器学习相比,DNN的识别处理精度要高得多,预计将会在汽车应用领域得到广泛应用。而采用传统处理器的DNN图像识别耗时较长,因为它依赖大量的乘积累加(MAC)计算。同时,采用传统高速处理器的DNN还存在功耗过高问题。
东芝利用可在硬件上实现深度学习的DNN加速器解决了这一难题。它具有三大特点。
- 并行MAC单元。DNN处理需要大量MAC计算。东芝的新设备配有四个处理器,每个处理器包含256个MAC单元。因此提高了DNN的处理速度。
- 减少了动态随机存取存储器(DRAM)存取。传统的系统级芯片没有本地内存,无法在靠近DNN执行单元的位置保存临时数据,并且在访问本地内存时产生较大功耗。同时,加载用于MAC计算的加权数据也会产生较大功耗。东芝新设备可在DNN执行单元附近执行静态随机存取存储器(SRAM),并将DNN处理分为多个子处理块,因此可将临时数据保存在SRAM内,从而减少了DRAM存取。此外,东芝还在加速器上增加了一个解压缩单元。可通过解压缩单元加载预先压缩并存储在DRAM中的加权数据。因此,降低了加载来自DRAM的加权数据时产生的功耗。
- 减少了SRAM存取。传统深度学习需要在处理DNN的每一层之后访问DRAM,因此功耗过高。该加速器在DNN的DNN执行单元中设计有流水线层结构,以便在一次SRAM存取期间执行一系列DNN计算。
新系统级芯片符合全球汽车应用功能安全标准ISO26262的要求。
东芝将继续提高所开发的系统级芯片的功率效率和处理速度,且东芝下一代图像识别处理器ViscontiTM5的样品发货将于今年九月启动。
|
注 |
||
|
[1] |
|
东芝在2015 IEEE国际固态电路会议上发表的一篇论文《面向图像识别应用采用基于颜色的对象分类加速器的1.9TOPS与564GOPS/W异构多核系统级芯片》中提及的图像识别系统级芯片 |
* ViscontiTM是东芝电子元件及存储装置株式会社的商标
* 所有其他公司名称、产品名称和服务名称均为其各自公司的商标。
关于东芝电子元件及存储装置株式会社
东芝电子元件及存储装置株式会社集新公司的活力与集团的经验智慧于一身。自2017年7月成为一家独立公司以来,我们已跻身领先的通用设备公司之列,并为客户和商业合作伙伴提供卓越的离散半导体、系统LSI和HDD解决方案。
公司遍布全球的2.2万名员工同心同德,竭力实现公司产品价值的最大化,同时重视与客户的密切合作,促进价值和新市场的共同创造。我们期待在目前超过8000亿日元(70亿美元)的年度销售额基础上再接再厉,为全球人类创造更加美好的未来。
有关公司的更多详情,请访问:https://toshiba.semicon-storage.com/ap-en/top.html
原文版本可在businesswire.com上查阅:https://www.businesswire.com/news/home/20190226005488/en/
免责声明:本公告之原文版本乃官方授权版本。译文仅供方便了解之用,烦请参照原文,原文版本乃唯一具法律效力之版本。
联系方式:
媒体垂询:
东芝电子元件及存储装置株式会社
公关与投资者关系部商业规划部
Motohiro Ajioka
电话:+81-3-3457-3576
semicon-NR-mailbox@ml.toshiba.co.jp
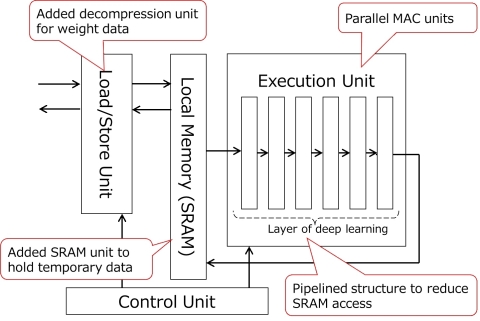
东芝:DNN加速器(图示:美国商业资讯)
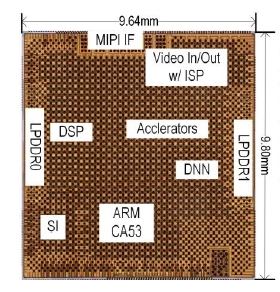
东芝:新开发的系统级芯片(照片:美国商业资讯)